
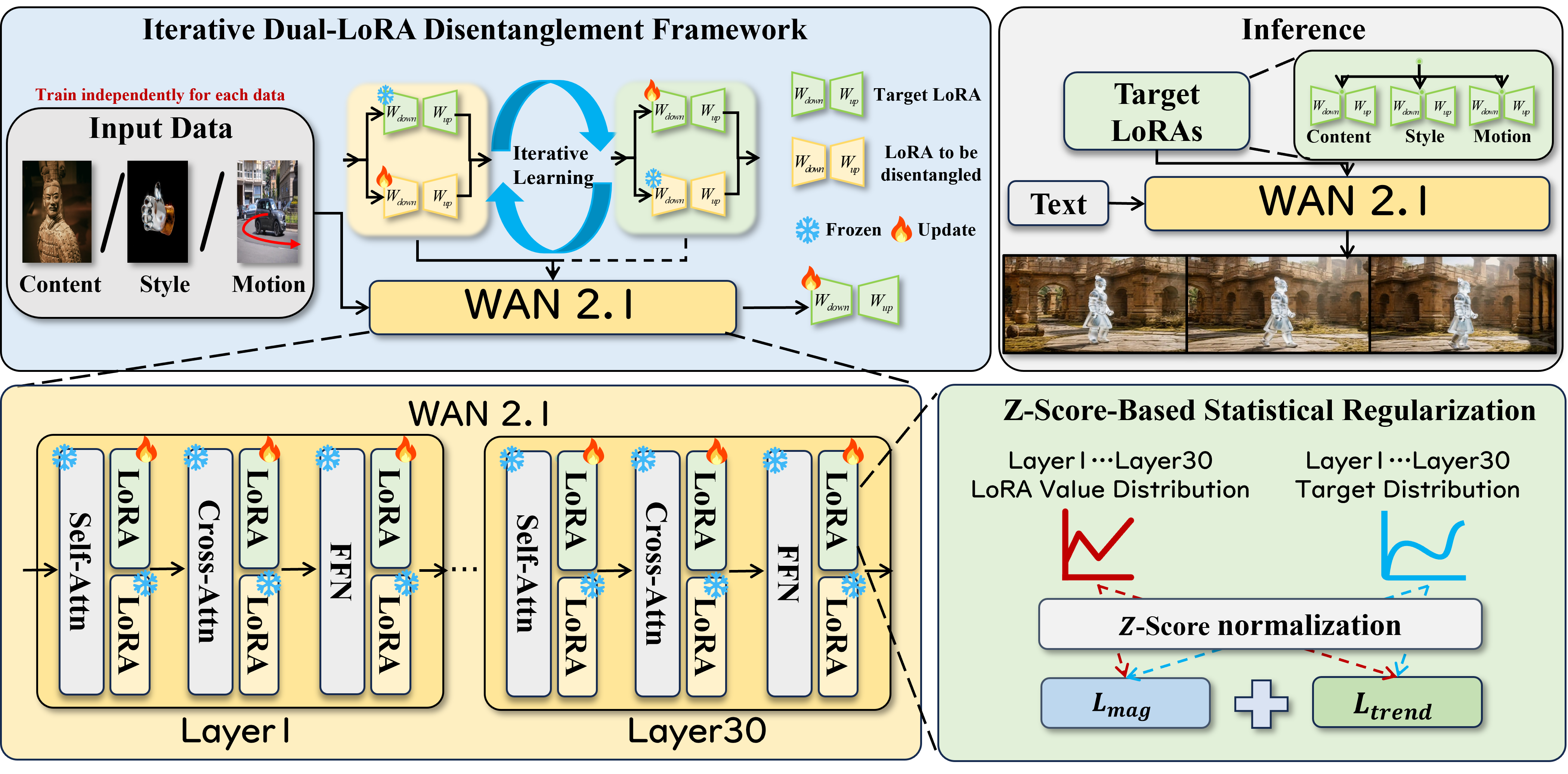
Video customization based on Text-to-Video (T2V) models aims to learn specific features from reference data to generate controllable videos. While significant strides have been made in image stylization and video motion customization, simultaneously controlling multiple concepts, such as content, style, and motion, remains a major challenge. In this work, we pioneer the systematic definition of the multi-concept Video customization task. To facilitate research in this area, we construct a comprehensive benchmark and propose DisCo-LoRA, a unified framework designed to tackle this problem by disentangling and flexibly recombining different concepts in two stages: (1) We decompose the objective into two sub-tasks: Content-Style and Content-Motion. Each sub-task is addressed using our Iterative Dual-LoRA Disentanglement Framework, which effectively disentangles distinct concepts within the data. (2) We identify layer-wise weight trends as crucial for LoRA identity, while weight magnitudes dictate composability. To harmonize these scales, we propose a Z-score-based statistical regularization that aligns weight distributions, preserving layer-wise trends while minimizing interference between different LoRAs. Extensive experiments show that Disco-LoRA excels in multi-concept video customization, effectively preserving appearance, style, and motion for controllable text-to-video generation.
Customizing videos with content, material appearance, and object motion.

"<o1> bear"

"made of <m5> colorful glass"
"<v3> running"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o1> bear, made of <m5> colorful glass, is <v3> running through a sun-dappled forest clearing where rays of light refract off its shimmering surface, casting rainbow patterns on the mossy ground and surrounding ferns."

"<o10> duck"

"made of <m4> Rusty metal"
"<v8> playing the guitar"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o10> duck, made of <m4> rusty metal, is <v8> playing the guitar on a weathered wooden porch at sunset, surrounded by overgrown wildflowers and scattered autumn leaves, with warm golden light casting long shadows and highlighting the metallic patina of its feathers."

"<o18> terracotta warrior"

"made of <m10> glass"
"<v4> running"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o18> terracotta warrior, made of <m10> glass, is <v4> running through a sunlit ancient courtyard scattered with shattered ceramic fragments and overgrown moss, where shafts of golden light pierce through crumbling stone archways, highlighting the translucent, fragile contours of its crystalline form."

"<o13> cat"

"made of <m9> colorful clay"
"<v9> playing the piano"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o13> cat, made of <m9> colorful clay, is <v9> playing the piano in a cozy, sunlit music room filled with vintage instruments, scattered sheet music, and warm wooden floors that reflect the soft glow of afternoon light streaming through lace curtains."
Customizing videos with content, art style appearance, and object motion.
"<o18> terracotta warrior"

"in <s3> watercolor painting style"
"<v7> playing the flute"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o18> terracotta warrior, is <v7> playing the flute amidst ancient ruins overgrown with moss and wildflowers under a soft golden sunset, in <s3> watercolor painting style."

"<o9> dog"

"in <s13> glowing style"
"<v4> running"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o9> dog, is <v4> running through a moonlit forest with bioluminescent mushrooms and shimmering leaves casting soft glows on the misty path, in <s13> glowing style."
"<o18> terracotta warrior"
"in <s11> cartoon line drawing style"
"<v5> running"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o18> terracotta warrior, is <v5> running through a sun-drenched ancient Chinese courtyard with scattered bronze artifacts, broken pottery shards, and fluttering silk banners in the wind, in <s11> cartoon line drawing style."

"<o16> teddy bear"

"in <s10> Chinese ink-wash style"
"<v8> playing the guitar"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o16> teddy bear, is <v8> playing the guitar on a quiet moonlit veranda surrounded by swaying bamboo and delicate cherry blossoms, in <s10> Chinese ink-wash style."
Customizing videos with content, material appearance, and camera motion.

"<o14> toy"

"made of <m8> sparkling diamonds"
"<c9> camera zooms in"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o14> toy, made of <m8> sparkling diamonds, is resting on a luxurious velvet display pedestal inside an opulent museum exhibit bathed in soft golden spotlights, <c9> camera zooms in."

"<o2> cat"
"made of <m10> glass"
"<c3> camera moves around"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o2> cat, made of <m10> glass, is perched on a sleek, minimalist windowsill overlooking a softly blurred cityscape at twilight, with ambient light refracting through its transparent form, <c3> camera moves around."

"<o7> dog"

"made of <m1> colorful clay"
"<c5> camera moves forward"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o7> dog, made of <m1> colorful clay, is sitting on a sunlit artisan's worktable scattered with clay tools, half-finished sculptures, and vibrant paint pots, <c5> camera moves forward."

"<o19> bear"

"made of <m3> gold"
"<c6> camera moves left"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o19> bear, made of <m3> gold, is perched atop a crystalline glacier under a twilight sky streaked with auroras, <c6> camera moves left."
Customizing videos with content, art style appearance, and camera motion.

"<o5> dog"
"in <s11> cartoon line drawing style"
"<c3> camera moves around"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o5> dog, is sitting playfully in a sunny suburban backyard with a picket fence, green grass, and a few scattered toys like a red ball and a chew bone, in <s11> cartoon line drawing style, <c3> camera moves around."
"<o13> cat"

"in <s22> sketch style"
"<c5> camera moves forward"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o13> cat, is perched on a sunlit windowsill overlooking a quiet autumn street with falling leaves and soft shadows, in <s22> sketch style, <c5> camera moves forward."

"<o15> panda"

"in <s1> watercolor painting style"
"<c8> camera moves up"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o15> panda, is sitting peacefully on a mossy rock beside a gently flowing mountain stream surrounded by misty bamboo groves and soft ferns, in <s1> watercolor painting style, <c8> camera moves up."
"<o9> dog"

"in <s17> melting golden 3D rendering style"
"<c5> camera moves forward"
DreamBooth
MotionDirector
UnzipLoRA+FlexiAct
Disco-LoRA (Ours)
"A <o9> dog, is standing on a sunlit marble pedestal surrounded by shimmering golden puddles that reflect its melting form, in <s17> melting golden 3D rendering style, <c5> camera moves forward."